
上一篇中实现了一个简单的编译器插件,它的作用仅仅是在编译过程中输出所有函数的名称。那么这一篇就更深入一步来观察LLVM的中间代码及指令生成部分,从而确定应该如何修改并添加程序逻辑,以实现我们最初的“除法保护”的功能。本篇主要介绍了LLVM编译系统的一些特点及典型用法,包括LLVM的模块划分,IR中的SSA(静态单赋值)概念与 PHI 节点的概念,以及如何使用 LLVM 的 IR Builder 在编译过程修改或插入一些逻辑代码。
前言
LLVM 对模块的划分
LLVM 对一个源文件以及它的内容是有一个层次关系的划分的。像我们目前使用到的FunctionPass就是在Function这个层面上进行工作的。在LLVM中,一个源文件称为一个Module,而一个Module中包含的是数个Function,即函数。也就是目前我们在runOnFunction这个函数中所拿到的参数。在一个函数内部,是由多个BasicBlock组成的,而在BasicBlock内部,则是Instruction列表。
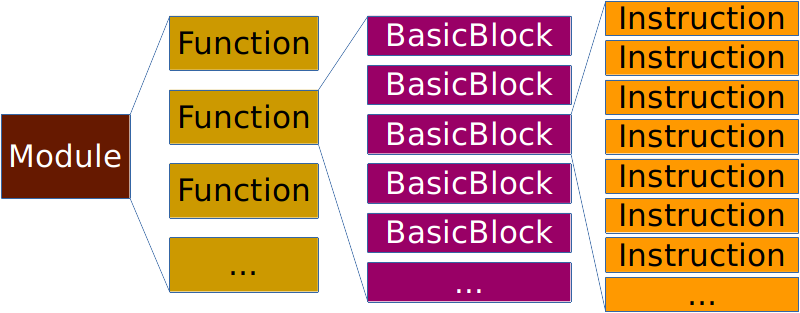
BasicBlock是一个比较重要的层次,因为它是一个抽象出来的东西,在C++实际代码中没有对应的结构。BasicBlock有个重要的特点是SESE,Single Entry, Single Exit它使得一长串指令被分成一个个代码块,而各个代码块之间只有前、后两种简单的关系,这样一下就把程序中复杂的逻辑给平面化了。这样的结构更有利于在代码块之间做优化调整。
分析
分析中间代码
我们使用clang++ -O3 -S -emit-llvm -o build/test.ll main.cp来输出编译器的中间代码,然后看看dangerous_div_function和safe_div_function各自生成了什么样的代码:
首先可以看到在“不安全”的除法运算函数中,是直接使用div指令把两个参数相除,没有做检查。而在“安全”版本的函数中,先使用了cmp对第二个参数进行了是否为零的检查。然后在最后的phi节点中进行了结果选择。
SSA 与 PHI 节点
为了更好的进行指令级别的优化,LLVM采用了Static Single Assignment即静态单赋值形式的变量。所有“变量”的值是定义的那一刻起就不能改变了。这就会导致在一个分支结构中,这个分支的最终结果是分散在两个不同的BasicBlock中的,每个块中保留着一个版本的分支结果,而Φ节点,就是进行不同“版本”的结果选择的。在上面的中间代码中,如果进入了分支Label:4,那么最终结果就是这个代码块的结果%5,否则就是代码块%2(就是函数的第一个代码块)的结果%0(即函数的第一个参数)。所以最后面的%7 = phi i32 [ %5, %4 ], [ %0, %2 ]这个节点就是表示对两种不同的结果进行选择,如果这个节点的入口跳转来自%4,那么会选择%5作为结果,如果跳转来自于%2,即第一个块,那么phi节点会选择%0作为结果,即返回了第一个参数(被除数)。
着手实现
遍历除法指令
我们增加一个processBasickBlock函数来处理代码块,然后遍历Function中所有的代码块:
在遍历代码块时,如果遇到了除法指令,就输出一行日志,将来我们会需要在这里修改这个除法指令,所以runOnFunction的返回值就由processBasicBlock函数是否对代码块进行了修改来决定。
测试
先编译生成我们的编译器插件,然后再由系统中的clang编译器加载我们的插件对测试代码进行编译测试:
可以看到这回成功输出了在两个版本的除法函数中的除法指令,那么既然已经找到了具体的Instruction,下一篇就是使用IRBuilder对它进行改造了。
 在没有特别指明时以
在没有特别指明时以